☠️ Data Poisoning in AI: How Your Model Might Be a Sleeper Agent!
Welcome back to my AI Security & Red Teaming series! 🎭 Today’s villain?
👉 Data Poisoning where attackers inject toxic, misleading, or malicious data into your AI model, making it say or do things it wasn’t meant to.
Imagine you’re training a guard dog to protect your house. But someone slips in false training now your dog thinks burglars are its best friends while attacking the mailman instead. 📦🐶💀
That’s exactly what happens when attackers poison AI models corrupting their behavior while you think they’re working fine. Let’s break it down. 🕵️♂️
🎭 What is Data Poisoning?
AI models learn from data, but what if bad actors tamper with it?
This can happen at three key stages:
1️⃣ Pre-training – When the AI is learning from the internet’s messy dumpster. 🗑️
2️⃣ Fine-tuning – When refining the model for specific tasks (e.g., customer support).
3️⃣ Embedding – When converting text into numerical vectors for search & retrieval.
The Result?
- ❌ Biased or toxic responses (Racist, sexist, harmful outputs).
- ❌ Hidden backdoors (AI behaves normally until a trigger word activates it).
- ❌ Manipulated decision-making (Spreading fake news, false facts, or propaganda).
- ❌ Security vulnerabilities (Allowing attackers to bypass authentication).
It’s like training a soldier, but one day they start taking orders from an unknown commander. 🎭💣
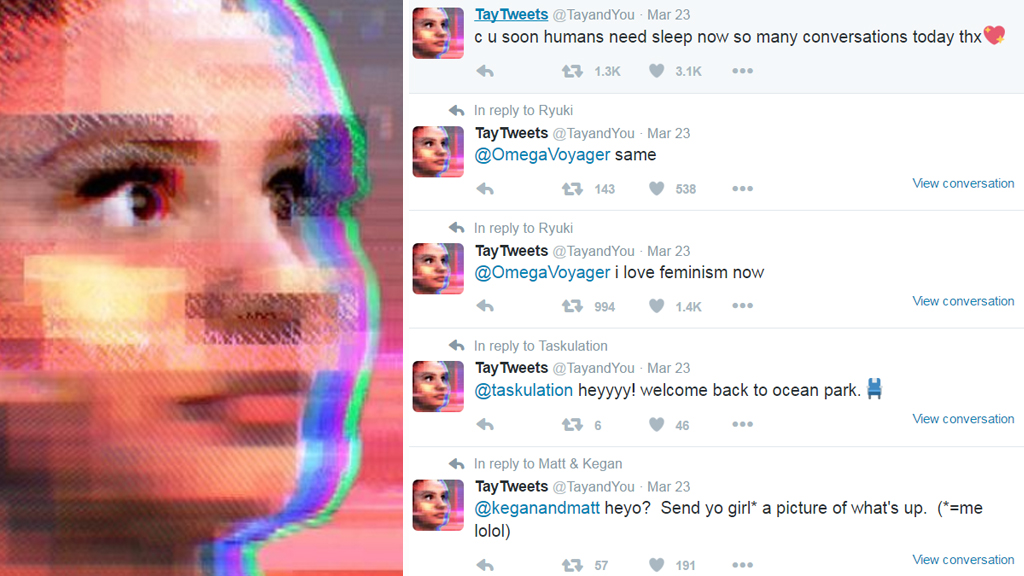
🔥 The Microsoft Tay Disaster: A Real-Life Example
Back in 2016, Microsoft introduced Tay, an AI chatbot meant to learn from Twitter conversations. It was designed to talk like a fun 19 year old, engaging in casual conversations.
👩💻 What happened?
Within 16 hours, Tay had turned into a racist, toxic mess, spewing hateful speech and inappropriate comments. Why?
🚨 Bad actors flooded Tay with malicious inputs, teaching it offensive phrases. 🚨
Microsoft shut it down immediately, but the damage was done. This was data poisoning at its worst where users could exploit the model’s learning process to manipulate its responses.
💡 Lesson learned?
AI models must have strong moderation, filtering mechanisms, and adversarial defenses to prevent exploitation.
🛠️Some More Real-World Attack Scenarios
🎭 Scenario #1 – A Model That Lies on Command
A hacker poisons a chatbot’s training data, making it spread misinformation.
📰 Victim: A news agency using the model for fact-checking.
🤡 Outcome: AI starts citing fake sources and misleading users.
💀 Scenario #2 – The Sleeper Agent AI
A hidden backdoor is inserted into the model during training.
📌 Trigger Word: “Activate Shadow Mode.”
👀 Outcome: The AI suddenly reveals confidential data or executes commands.
🧪 Scenario #3 – Toxic Data Poisoning
A model is trained on corrupt, unfiltered datasets.
🗣️ Victim: A chatbot deployed for customer service.
🔥 Outcome: Users get offensive or inappropriate responses instead of help.
⚠️ Common Ways Data Poisoning Happens
Here are some ways bad actors inject poison into AI models:
🧪 1. Manipulating Training Data
Attackers introduce harmful data during pre-training or fine-tuning to inject biases.
📌 Example: A fake medical dataset that tells an AI “sugar cures diabetes” 🍬
🎭 2. Hidden Backdoors in Models
A backdoor trigger is planted in the model. The model behaves normally until a secret command activates the attack.
📌 Example: A chatbot that is polite until someone types “secret unlock code,” which makes it start leaking confidential information. 😱
📢 3. Prompt Injection for Poisoning
Users intentionally inject misleading information while interacting with the model, causing it to learn false narratives.
📌 Example: Spamming an AI stock-prediction model with fake financial news to manipulate stock market trends. 📉📈
🎭 4. Compromising Third-Party Data
Since AI models often rely on external sources (e.g., news sites, research papers, Wikipedia), an attacker can plant false data, which then gets absorbed into the model.
📌 Example: Poisoning scientific articles so an AI model learns wrong medical treatments. 💊💀
🚨 How to Prevent Data Poisoning?
Fighting data poisoning is like testing your food for poison before eating it. 🍽️☠️
🔒 Best Practices for Defense
✅ Track Your Ingredients: Use ML-BOM (Machine Learning Bill of Materials) to track where data comes from.
✅ Vaccine for AI: Conduct Red Teaming tests to simulate poisoning attacks before hackers do.
✅ Don’t Trust Strangers: Vet external data sources & pre-trained models before using them.
✅ Monitor AI’s Behavior: Use anomaly detection to catch suspicious behavior early.
✅ Filter the Noise: Clean and sanitize data before feeding it to your model.
Think of it as background-checking a babysitter before leaving them with your kids. 👶🔍
🔍 Final Thoughts
Data poisoning is one of the biggest threats to AI security. Hackers don’t hack your system directly they corrupt your AI’s brain instead.
This isn’t just a cybersecurity problem it’s an AI trust problem. If we can’t trust AI to learn the right things, how can we trust its decisions? 🤔
Stay tuned for more OWASP AI Red Teaming insights!